📍Neural Network
- 인공지능의 한 분야로, 인간의 신경망을 모방한 컴퓨팅 시스템.
- 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)로 구성
📍perceptron
- 이진분류 모델을 학습하기 위한 지도학습기반의 알고리즘 (개 고양이 분류)
- 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘
- 단순한 선형 분류기로, 입력을 받아 각 입력에 가중치를 곱한 후, 그 합이 특정 임계값을 넘으면 1을 출력하고 그렇지 않으면 0을 출력하는 방식으로 작동
- 1개의 뉴런으로만 구성

- 입력값(X): 퍼셉트론에 들어가는 신호입니다. 이 입력값은 특성(feature)이라고도 하며, 각각의 입력값은 그에 해당하는 가중치와 곱해집니다.
- 가중치(W): 각 입력 신호가 결과에 미치는 영향력을 조절하는 매개변수입니다. 학습 과정에서 이 가중치는 지속적으로 조정됩니다.
- 활성화 함수(Activation Function): 가중치가 적용된 입력값의 합을 받아서, 출력값을 결정하는 함수입니다. 퍼셉트론에서는 주로 단위 계단 함수(Step Function)가 사용되어, 특정 임계값을 넘으면 1을, 넘지 않으면 0을 출력합니다.
- 출력값(Y): 활성화 함수를 거쳐 최종적으로 퍼셉트론이 내놓은 결과값입니다.
☑️종류
단층 퍼셉트론 : 은닉층 x
- 디지털 논리 회로 개념에서 AND, NAND, OR 게이트를 구현
다층 : 은닉층 1개이상 존재
- XOR 게이트를 구현
심층신경망(DNN) 딥러닝 : 2개 이상의 은닉층을 가짐
☑️학습 과정
- 가중치를 초기화합니다.(매개변수 선택)
- 각 입력값에 대해 가중치를 곱하고, 그 합에 활성화 함수를 적용하여 출력값을 얻습니다.
- 출력값과 실제 값(레이블)을 비교하여 오차를 계산합니다.
- 오차를 줄이기 위해 가중치를 조정합니다. 이 과정에서 일반적으로 경사 하강법(Gradient Descent)이 사용됩니다.
- 모든 학습 데이터에 대해 2~4단계를 반복합니다.
퍼셉트론은 비교적 간단한 구조로 인해 구현이 용이하고, 선형 분리가 가능한 문제에 대해서는 높은 효율성을 보입니다. 그러나 XOR 문제와 같이 선형 분리가 불가능한 문제에 대해서는 퍼셉트론으로 해결할 수 없다는 한계가 있습니다. 이러한 한계를 극복하기 위해 다층 퍼셉트론(Multi-layer Perceptron, MLP)과 같은 발전된 형태의 인공신경망이 연구되었습니다.
☑️활성화 함수
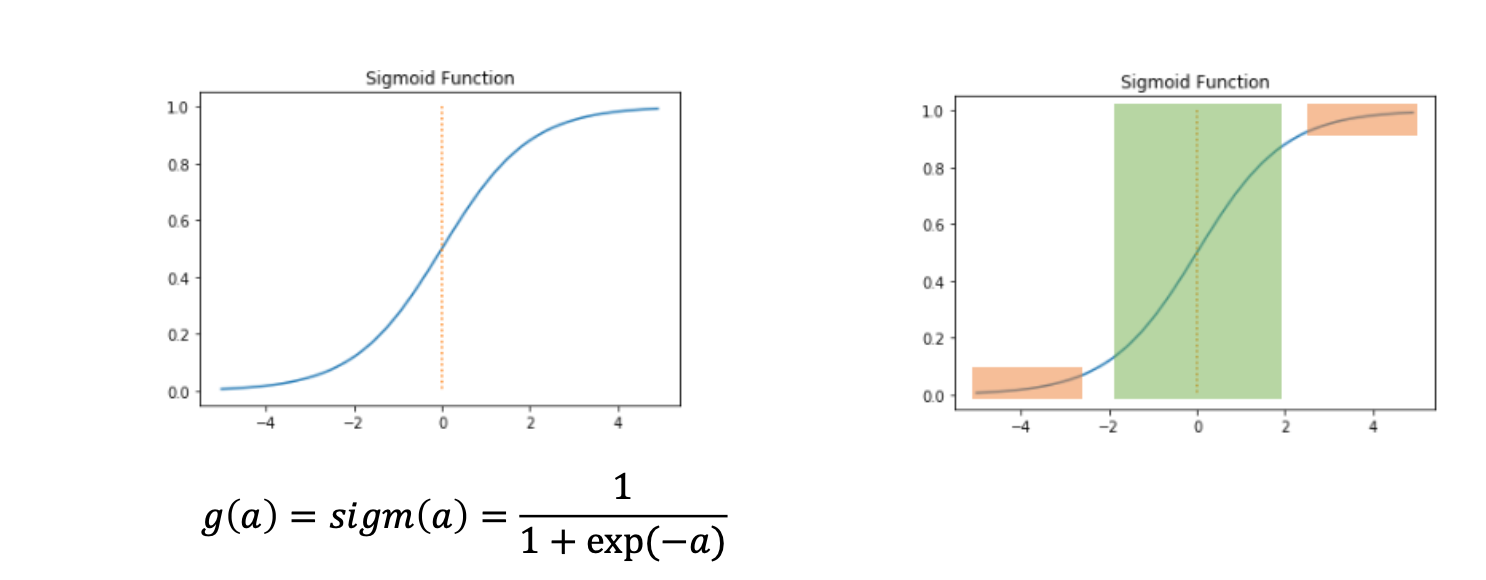
1) sigmoid :
- 함수의 출력 값이 0~1
2) hyperbolic Tangent:
- 함수의 출력값이 -1 ~ -1
- hidden layer에서 많이 사용됨
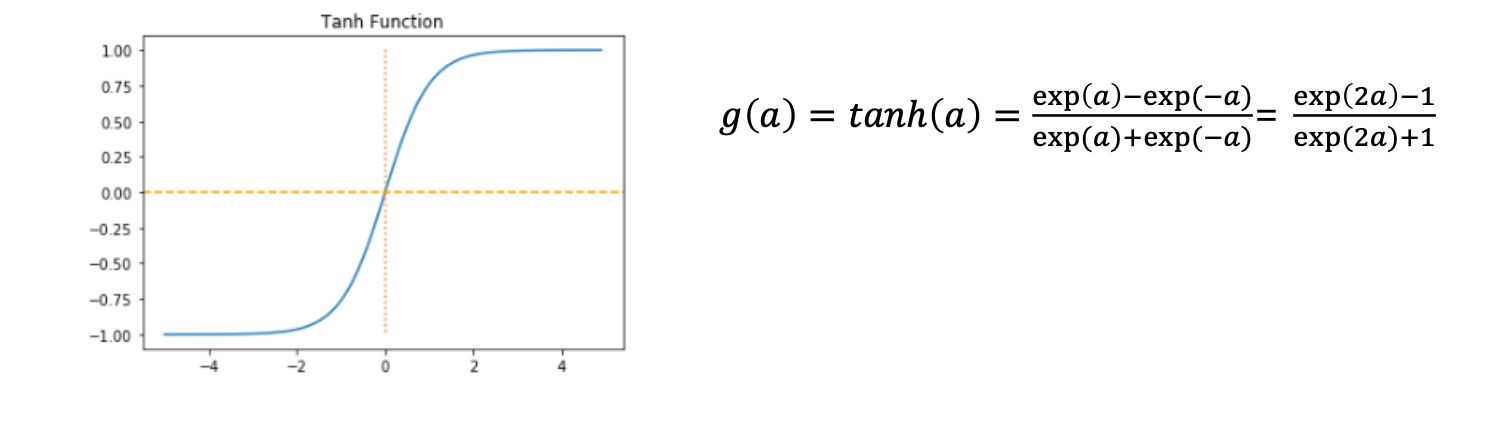
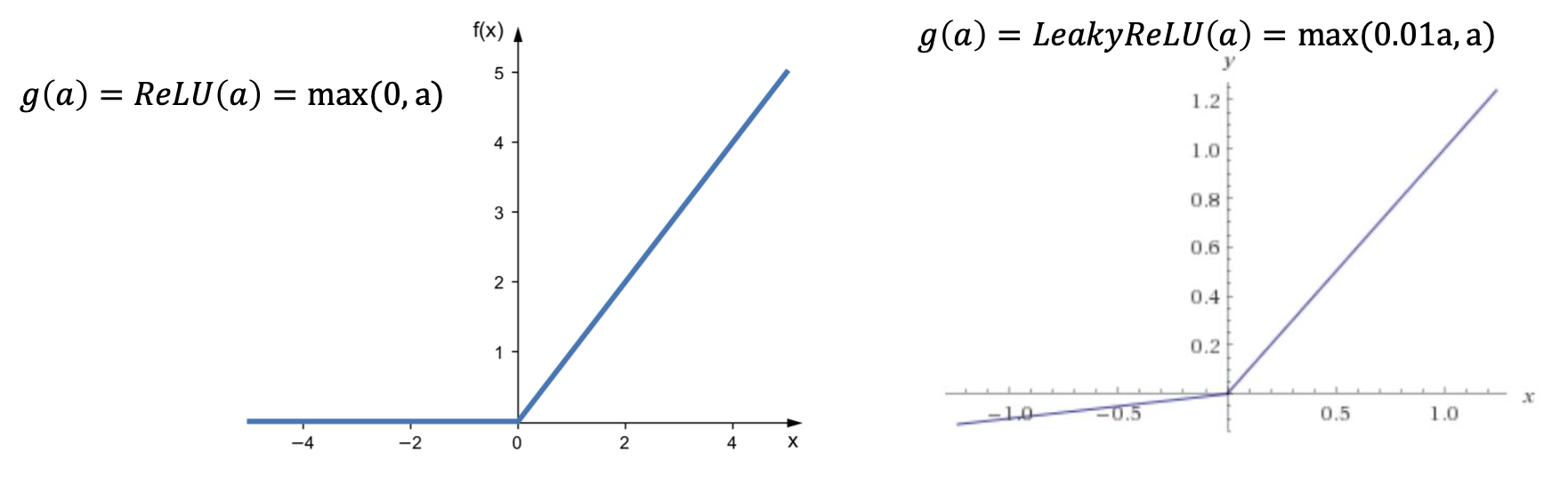
3) relu:
- 음수 입력 -> 0 , 양수 그대로
☑️Gradient(기울기) Descent 경사 하강법 (최적화 알고리즘)
- 입력 값과 목표 값의 관계가 가장 잘 맞춰지도록 가중치 w를 찾도록
- Cost function을 최소화하는 파라미터를 찾기 위한 알고리즘
- 경사 하강법(Gradient Descent)은 머신 러닝과 딥 러닝에서 널리 사용되는 최적화 알고리즘입니다.
- 기본 아이디어는 cost function (비용 함수)의 기울기를 계산하여 이 기울기가 가리키는 방향으로 매개변수를 조금씩 조정해가며 최소값을 찾는 것
☑️작동 원리
1) 매개변수 선택:
먼저, 매개변수(가중치)에 대한 초기값을 선택합니다. 이 값은 무작위로 선택되거나 특정 규칙에 따라 초기화될 수 있습니다.
2) 기울기 계산:
비용 함수의 현재 매개변수에 대한 기울기(편미분 값)를 계산합니다. 이 기울기는 매개변수를 조정해야 할 방향과 크기를 알려줍니다.
3) 매개변수 업데이트: 계산된 기울기와 학습률(Learning Rate)을 곱한 값을 현재 매개변수에서 빼주어 매개변수를 업데이트합니다. 학습률은 매개변수를 얼마나 크게 조정할지를 결정하는 값입니다.
4)반복: 위의 과정을 비용 함수의 최소값에 도달할 때까지 반복합니다.
Cost function
▪ 전체 데이터에 대해 평균적으로 얼마나 잘못 맞추었는지
- 모델의 예측값과 실제값 사이의 차이를 측정하는 함수
- 이 함수의 값이 작을수록 모델의 성능이 좋다고 판단
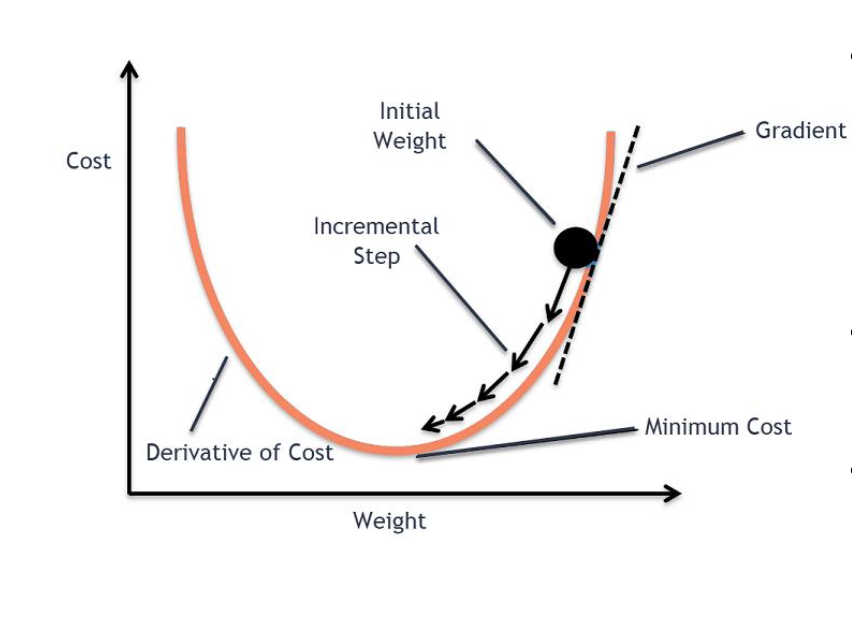
Gradient의 값
▪ If 0 : 현재 weights이 optimal → 학습 종료
▪ Not 0: 현재 weights은 optimal이 아님 → 학습 진행
• Gradient가 0이 아닌 경우, gradient의 반대 방향으로 이동 ( 현재 위치에서 기울기가 내려가는 방향)
Loss function
• 출력 𝑦가 얼마나 실제 𝑡에 가까운지
• Regression: squared loss
▪ 𝐿 =1/2 (𝑡 − 𝑦)2
• Classification: cross-entropy
▪ 𝐿 = − σ𝑖 𝑡𝑖𝑙𝑜𝑔𝑝𝑖
☑️weights의 업데이트와 관련된 세가지 방법
1) [확률적 경사 하강법(Stochastic Gradient Descent, SGD)]
- 개별 training example에 대한 loss function 계산하고 gradient를 업데이트
- 각 반복마다 단 하나의 샘플을 무작위로 선택하여 기울기를 계산합니다. 이 방법은 빠르게 수렴하며, 미니 배치 경사 하강법보다 더 불규칙한 수렴 과정을 보입니다.경사 하강법은 그 자체로 강력한 도구이며, 다양한 머신 러닝과 딥 러닝 모델을 최적화하는 데 필수적인 방법입니다.
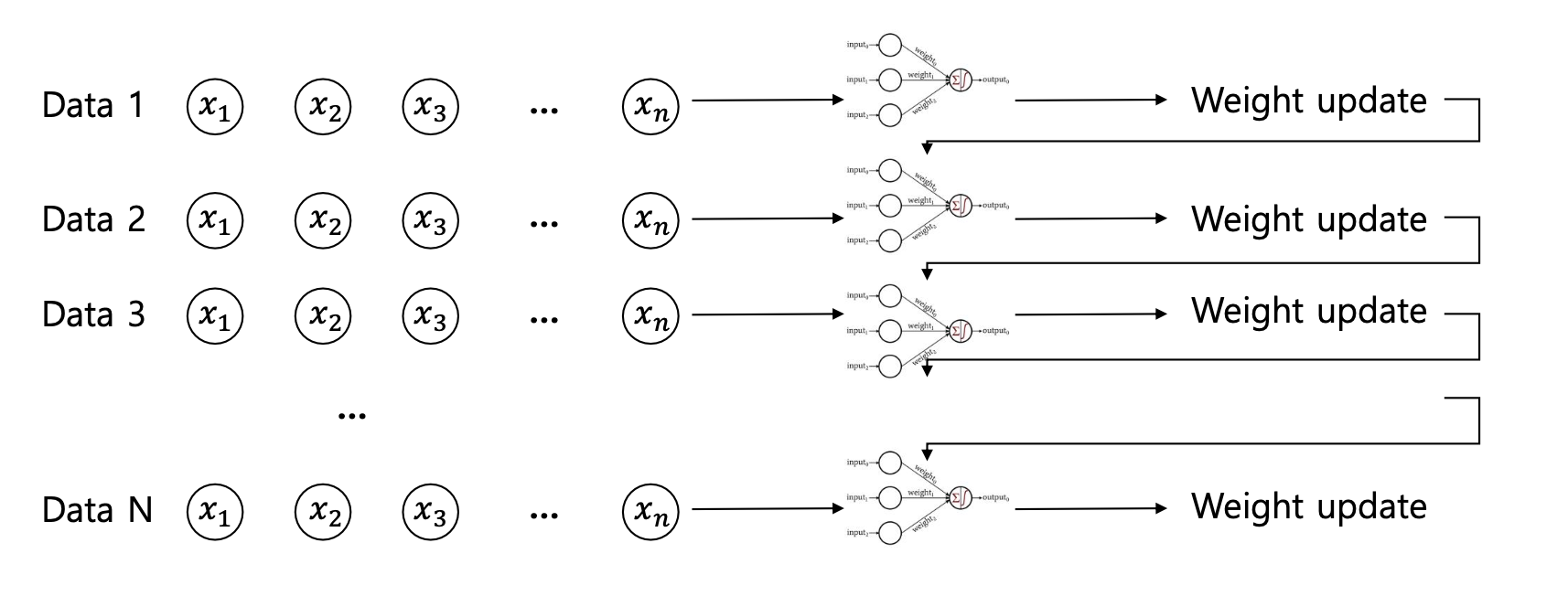
2) [배치 경사 하강법(Batch Gradient Descent)]
- 전체 데이터셋에 대해 비용 함수의 기울기를 계산합니다.
- 네트워크 weights을 고정한 후, 모든 training examples에 대한 loss function을
계산한 후에 gradient를 업데이트
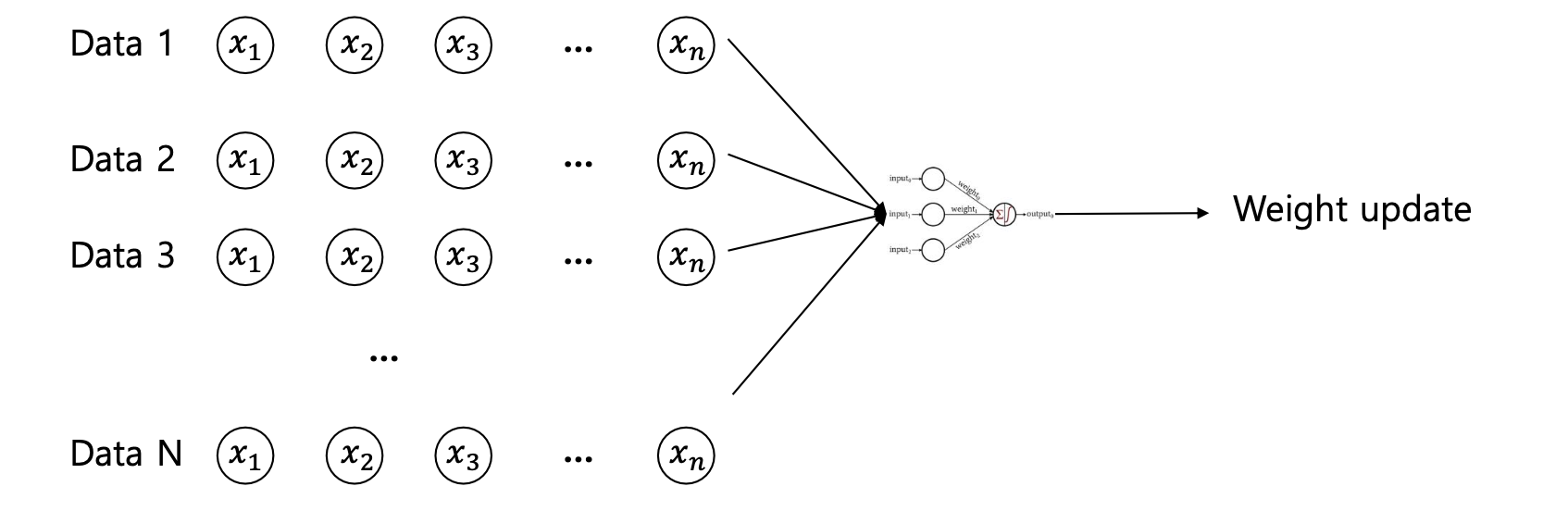
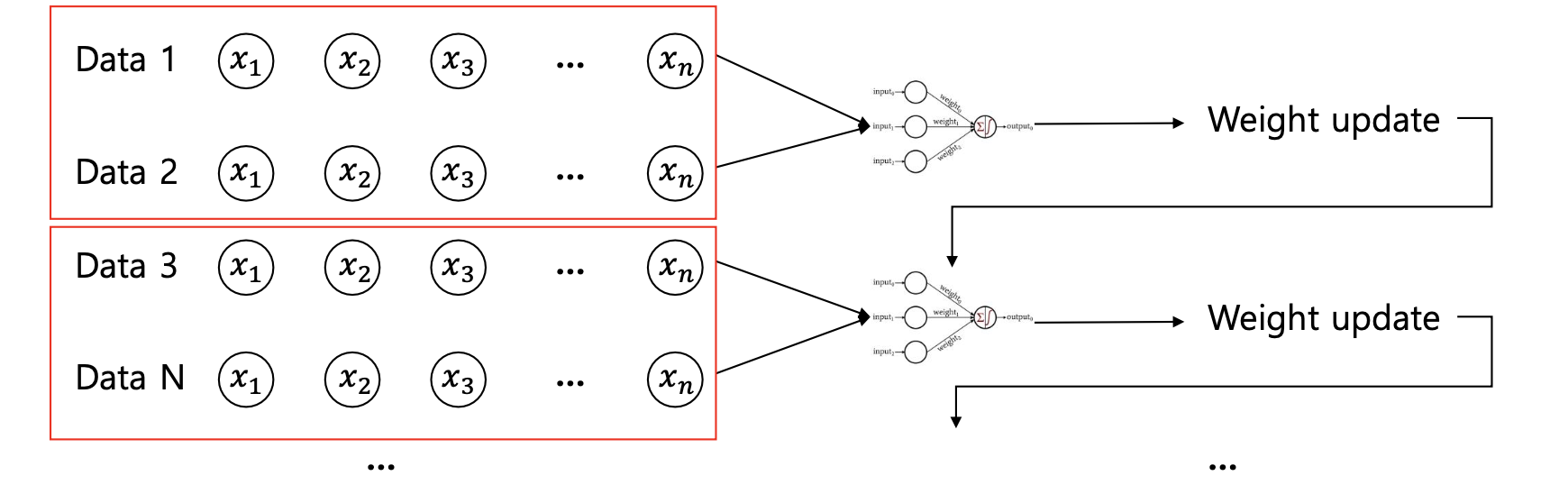
3)[미니 배치 경사 하강법(Mini-Batch Gradient Descent)]
- N개의 전체 training examples 중에서 n개의 mini-batch examples를 구성하고
n개의 examples를 사용하여 gradient 업데이트
- 데이터셋을 작은 배치로 나누어 각 배치에 대해 기울기를 계산합니다. 이 방법은 전체 데이터셋과 비교하여 빠른 수렴을 보여주며, 컴퓨터 메모리를 효율적으로 사용할 수 있습니다.
☑️[가중치 업데이트 ]
- Gradient Descent에서 Weights(가중치)를 업데이트하는 양은 주로 학습률(learning rate)과 경사(gradient)에 의해 결정
- 최적의 가중치를 찾는 것이 Gradient Descent 알고리즘의 기본입니다.

예를 들어, 만약 학습률이 0.01이고 현재 가중치에 대한 손실 함수의 경사가 0.5라면, 가중치는 다음과 같이 업데이트됩니다:
[
w := w - 0.01 \times 0.5
]
이렇게 하면 가중치는 0.005만큼 감소하게 됩니다.
이 과정을 반복하여 최적의 가중치를 찾는 것이 Gradient Descent
[학습률(Learning Rate)]
- 가중치를 얼마나 크게 조정할지를 결정하는 매개변수입니다.
- 너무 작으면 학습이 느려지고, 너무 크면 최적화가 불안정해지고 학습 과정에서 발산할 수 있습니다.
- 일반적으로 0.01 또는 0.001을 사용
- 초기에는 learning rate을 크게 잡고, 학습이 진행될 수록 learning rate이 줄어들 수 있도록 해주는 게 좋음